Spark MLlibで動かすScala製機械学習サーバ【PredictionIO勉強会 #01】に参加しました。
PredictionIOというのはApacheのincubatingプロジェクトで、機械学習エンジンを手軽にweb serviceとして動かすことのできるものです。
PredictionIOはSalesforceに買収されて、Einsteinというサービスのコアとなっているようです。
動作イメージはpredictionIOのサイトの図を見て頂くと良いかと思いますが。
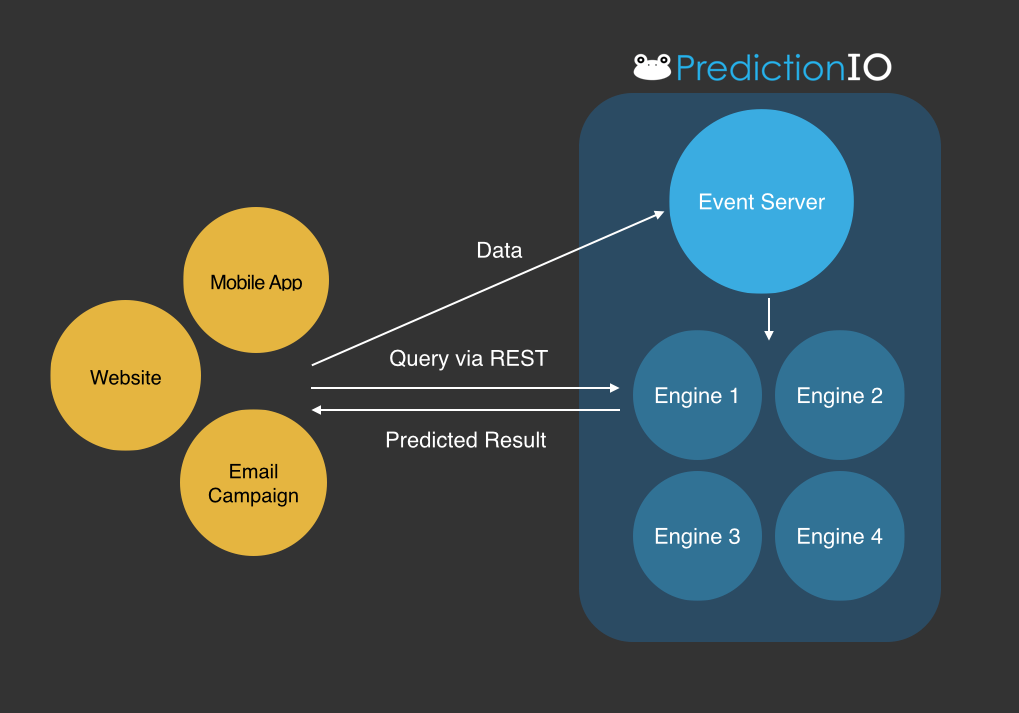{kind=link}
- 機械学習はSparkのMLlibで行われる。
- 学習データの投入は基本は CLI ツールから行うが、REST API でデータ投入もできる。
- 学習データは RDBMS か HBase 上に保存。学習データ以外にメタデータ(RDBMSかElasticsearch上)、モデルデータ(RDBMS, HDFS, LOCALFS上)も保存する必要がある。
- 機械学習されたモデルを使って予測が出来る。
- 予測サービスは REST API で呼び出せる。計算済みのモデルを用いて、Spark で予測してレスポンスを返す。
という、MLlibのアルゴリズムの周りの追加機能として、データの投入やRESTでのアクセス機能を提供するフレームワーク、と考えると良いかと思います。
あと特徴としては、Engine Template Galleryにあるように、単にMLlibの薄いラッパーというよりは、かなり具体的な(例えばProduct RankingとかViewed This Bought Thatのような)計算モデルがテンプレートとして提供されていることでしょうか。特に商品レコメンド関係のテンプレートが充実しているような気がします。
検索するとDeploying with AWS CloudFormationというページも見つかりました。Cloud Formationで簡単にPredictionIOのサービスを起動できるようですね。
良さそうなフレームワークなのですが、話を聞く限りでは、
- まだ成熟してるとはいえない。マニュアルの不備とか、開発ブランチを落として動かしてね、みたいなところとか。
- Spark 1.x ベース。RDD を使うこと前提なフレームワークに見えるので、2.x への対応はどうなるのだろう、とか。
- これ、Event Server は水平スケールするのかな?というのがちょっとよく判らなかった。
という辺りが、もうちょっとかな、と思えたところではあります。ただ、scalaのコードの読み書きに抵抗が無いなら、今話題のフレームワークとして興味深いと思います。余裕が出たら、ちょっと手を出してみたい感じはします。