ちわっす!インフラ担当の池田(@mikeda)です。
今日はサーバ監視周りの話です。
まずNaviPlusでは、サーバ監視にNagiosとMuninを使っています。
普通ですね!
気をつけていることは、ちゃんとサービスも監視する(正常なHTTP応答、応答速度など)ということでしょうか。
まぁこのへんは今日の本題ではないので別の機会に話します。
システム運用してると、こんな情報も見たいなーというのが出てきます。
例えば、今回紹介するのはこんなのです。
- 障害発生時(例えば昨日のXX時XX分)の全サーバのプロセスリスト
- 全サーバのリソース使用状況のザックリとしたレポート
- あのDBでXX時ごろに流れてたクエリはどんなのか
- 去年のセール時のアクセス数やサーバ負荷の状況が見たい
- 本番サーバでtmuxを起動しっぱなしの人がいないか
こういう既存ツール(うちだとNagios/Munin)にマッチしないものって放置されがちですよね。
ただこういうのをどうやって仕組み化して簡単に見れるようにするか、ってのは運用において重要なポイントだと思ってたりします。
まずはApacheのOption Indexesについて紹介
ApacheのOption Indexesについてだけ先に説明しておきます。
NaviPlusの内部向け管理サーバのApacheにはこういう設定が入ってます
NameVirtualHost *:80
<VirtualHost *:80>
ServerName sysadm
ErrorLog "/var/log/httpd/sysadm.error_log"
CustomLog "|/usr/sbin/cronolog /var/log/httpd/sysadm.access_log.%Y%m%d" combined
DocumentRoot /var/www/html
<Directory "/var/www/html">
Options Indexes FollowSymLinks ### ←ここがポイント
Order deny,allow
Deny from all
Include conf/extra/allow_from_naviplus.conf
</Directory>
</VirtualHost>
こうするとブラウザでアクセスした時にOSのディレクトリ構造がそのまま見れます。
※外部公開は絶対にやらないように!
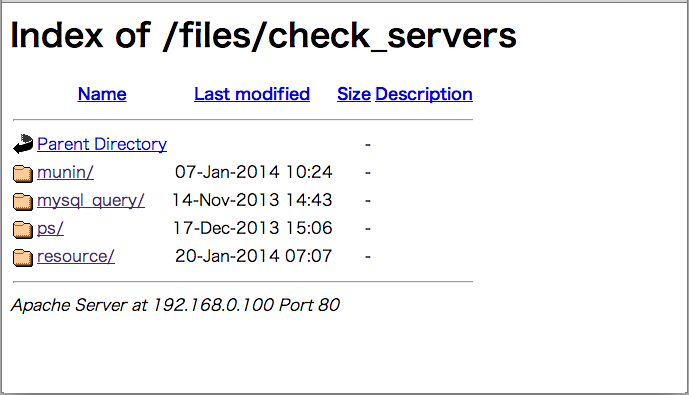
ここに必要な情報を配置していくと簡単な管理画面っぽく使えます。
テキスト、HTML、画像など、ルールを決めてなんでも突っ込んでます。
(WEBDAVも有効化しておくとファイルのアップも出来て便利かもですね)
全サーバのプロセスリスト
これは『Nagiosのアラートメールを受け取ってサーバにログインしたけど、既に負荷は下がっていて何が原因だったかわからない』という時の調査等に使っています。
2分毎に全サーバの『ps aux』の結果を取得していて、さっきの管理サーバにアクセスしてポチポチたどって行くと見れます。
各サーバ名のディレクトリがあって
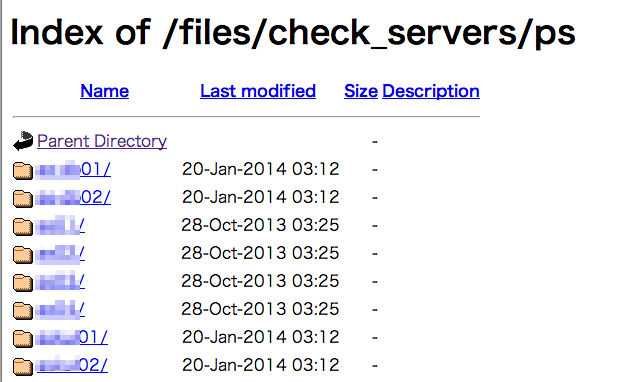
日付ディレクトリがあって
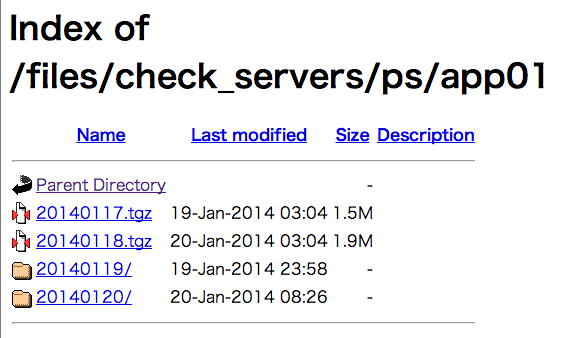
2分毎に作成されたテキストが並んでて

クリックするとps auxの出力が見れます
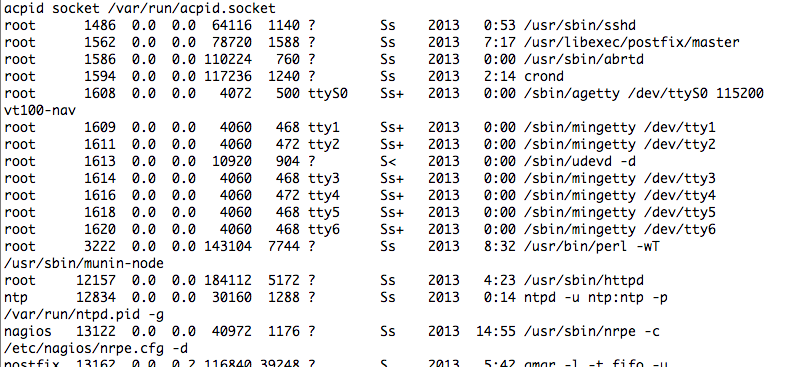
この情報は管理サーバ上のcronで収集しています。
### 全サーバのプロセスリストを取得 */2 * * * * /naviplus/cron/check_servers/ps.sh
実行されてるスクリプトはこんな感じです
#!/bin/bash
export PATH=/usr/local/bin:/bin:/usr/bin
# このファイルに監視対象サーバ名を並べてます
# 将来的には更新漏れの起こりづらい別の仕組みにするかも
# →構築/管理ツールと連携とか、各サーバからPUSH方式にするとか
server_list='/naviplus/sv.list'
DAY=`date +%Y%m%d`
MIN=`date +%H%M`
BASE_DIR=/var/www/html/check_servers/ps
cd $BASE_DIR || exit 1
# 1台ずつやると時間かかるから一気に実行
# サーバ台数ぶん一気はやりすぎ感あるw
while read host;do
mkdir $host 2>/dev/null
mkdir $host/$DAY 2>/dev/null
ssh $host "ps aux" > $host/$DAY/${host}_${DAY}_${MIN}.txt &
done < $server_list
wait
サーバのリソース使用状況サマリ
さっきと同じようにたどって、日次の全サーバのリソース使用状況がサマリHTMLで見られるようになっています。
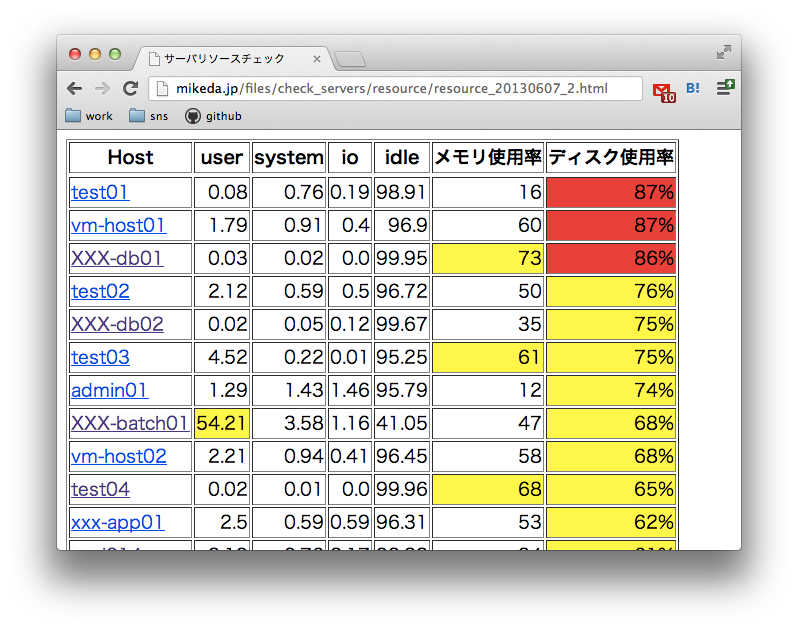
『各サーバのリソース使用状況をパッと確認する』ことで、障害の予防やサーバ購入計画の作成などに役立てています。
極力、手間をかけずにチェックできるように、項目ごとのソート機能をつけたり危なそうなのに色付けしたりしてます。
これも現状、管理サーバ上のcronで情報を集めています。
### サーバのリソース使用状況のサマリページを作成 0 7 * * * /naviplus/cron/check_servers/check_server_resource.rb > /var/www/html/check_servers/resource/resource_`date +\%Y\%m\%d`.html
細かいことは以前、個人ブログに書いたのでそっちを見て下さいw
MySQLのクエリ解析
同じようにたどってくと、ピークタイムは外してますが各DBの数時間おきのクエリ解析の結果が見れます。
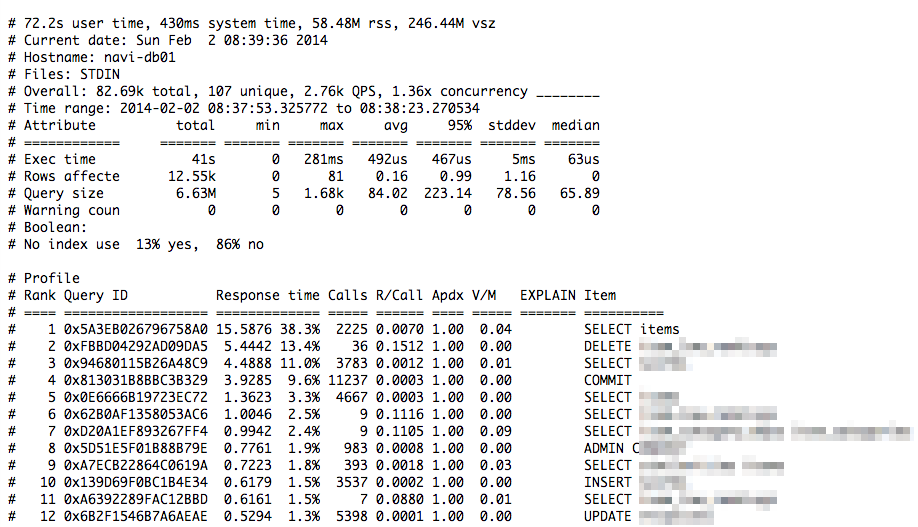
最近サービスが重くなってるとかバッチに時間がかかるとかって時に、MySQLのどのクエリにどの程度時間がかかってるかを確認するのに使ってます。
これも細かいところは個人ブログを参照して下さい。いろいろ調整してるものの基本的な仕組みは同じです。
過去のセール、イベント時のアクセス数やサーバ負荷状況
『過去のセール時のアクセス数やサーバ負荷を確認したい』というのはけっこうあります。
ただmuninの過去のグラフはどんどん丸まっていきますし、ずっと残してる保証もありません。
というわけで、セールなどの後はmuninのグラフ画像をマルっと管理サーバにコピーして、いつでも見たり、Redmineなどにリンク貼ったりできるようにしてます。
各セール、イベントごとにディレクトリがあって、
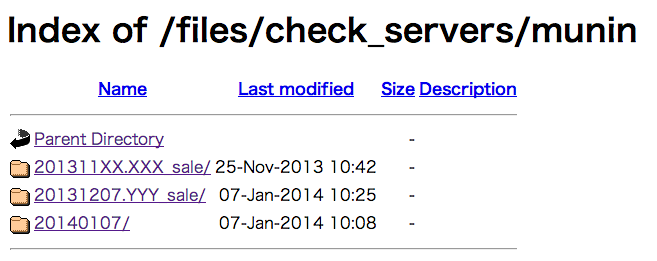
関係する各サーバ名のディレクトリがあって
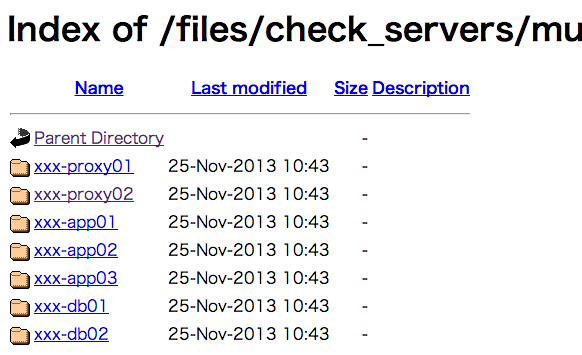
muninのグラフ画像が並んでます
クリックすると当時のグラフ画像が見れます
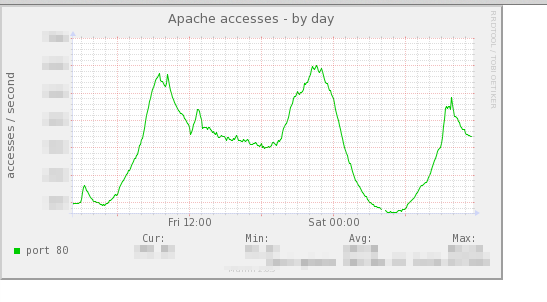
これはMuninサーバの/var/www/html/muninあたりから、必要そうなサーバの必要そうなグラフ画像を全部抜き出して管理サーバにコピーしてるだけです。
※グラフ画像を動的生成している場合は事前に一度表示させるなどの工夫が必要です。
画像だけじゃなく、HTMLもいっしょに抜き出してゴニョゴニョするともうちょっと見やすくなりそうですね。
tmuxの起動しっぱなしチェック
本番サーバで起動したtmuxが放置されていて、『作業しようとしたファイルが開かれている』、『放置されたコマンドがメモリを食いまくっている』、などがたまにあるので毎朝チェックしています。
これも管理サーバ上のcronスクリプトで毎朝チェック、放置tmuxがあればこういうメールを飛ばすようにしています。
tmux check @xxx-app05 Mon Jan 27 11:21:06 2014 tmux new -s ikeda @yyy-db01 Mon Jan 27 16:52:38 2014 tmux new -s yoshida
スクリプトはこんな感じです。
#!/bin/bash
PATH=/usr/local/bin:/bin:/usr/bin
mail_addr="xxx@example.jp"
server_list=/naviplus/sv.list
tmp_message=/tmp/check_tmux_message.$$
cnt=0
while read host;do
output=`ssh -n $host "ps -o lstart=,cmd= -C tmux"`
if [ $? -eq 0 ];then
echo "@$host"
echo "$output"
echo
cnt=$((cnt+1))
fi
done < $server_list > $tmp_message
if [ "$cnt" -ne 0 ];then
cat $tmp_message | mail -s "tmux check" $mail_addr
fi
/bin/rm $tmp_message
同じ仕組みを使って、いくつかのちょっとしたチェックと警告メール送信を実施してます。
まとめ
というわけでシステム運用をちょっと楽にする、プラスαなサーバ監視の話でした。
特にすごいシステムやツールがあるわけでも、難しいことしてるわけでもないです。
ちょっとした工夫の組み合わせです。
大事なのは『こういう情報も見れたらもっと運用が楽になる、サービスの品質を上げられる』というのを1つずつ、できるだけ手間をかけずにちゃんと形にしていくことだと思います。
運用系エンジニアの腕の見せどころですね!
※Fluentd/GrowthForecast/ElasticSearch+Kibanaも導入検証中なのでもうすぐなんか書きます!